
Post training with RL
what it can and cannot do

RL post-training seems like an elegant solution to teach the LLM to get better at stuff - but lately I’m thinking it isn’t a lot of teaching than making some inference paths more probable than others.
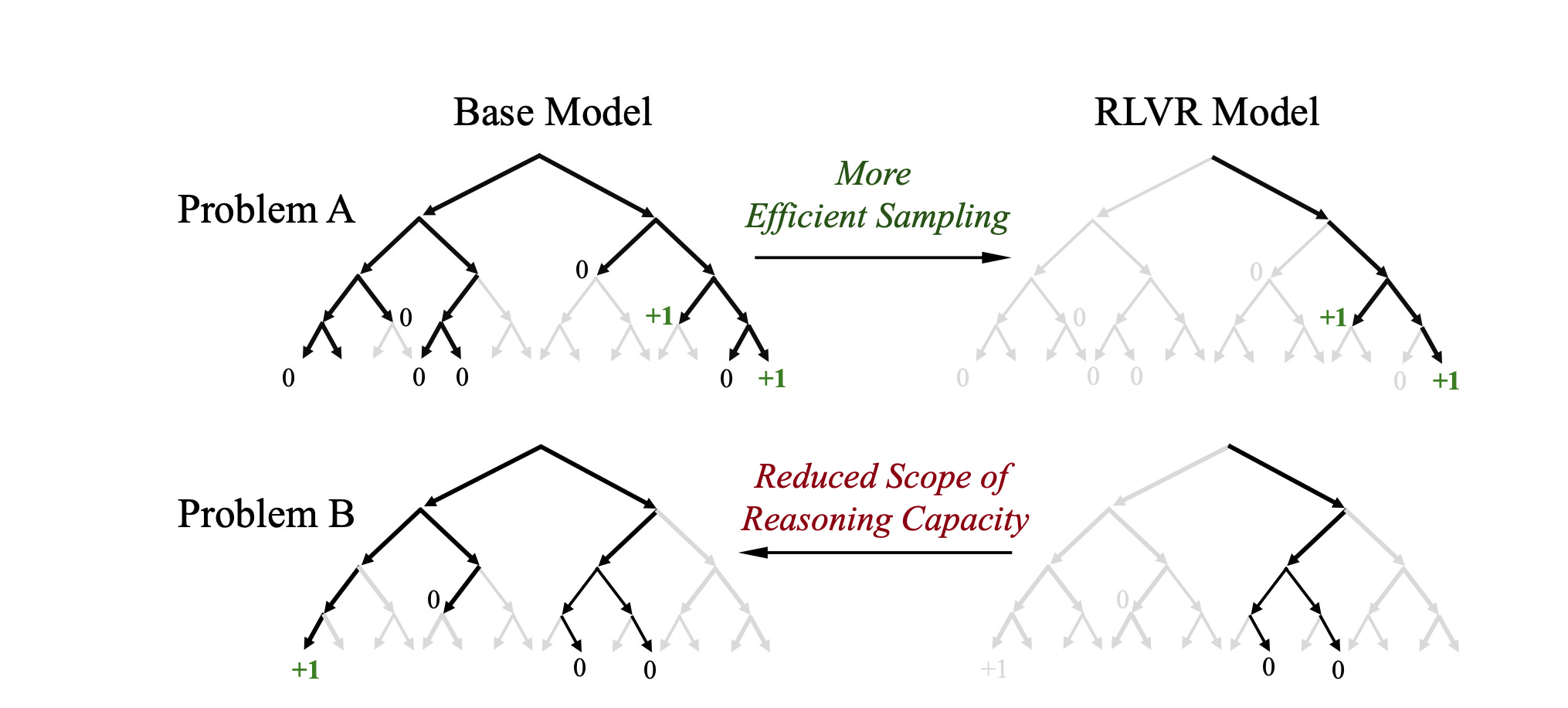
A corollary to this is that if the correct reasoning path has zero probability in the abse model, then no amount of RL can help. P(good path) should always be > 0. This also shows up in a GPU model lecture by Daniel Han(unsloth guy). Another corollary is that RL reduces the generalisability of the model by reducing the probability of alternative approaches. I think it can be good for narrow tasks. So the base model better be good.

Another insight from Daniel is that although process supervision seems like a good idea, it involves rewarding parts of the generated text differently based on how much they contributed to the final reward. But does not sound scalable. The bitter lesson is just to keep rewards simple and throw more data at it.
Another takeaway from the talk is the emphasis on env creation. How labs are creating new and new environments to do RL in.
First, we implement a cold-start phase utilizing the DeepSeek-V3 (DeepSeek-AI, 2024) methodology to unify reasoning and tool-use within single trajectories. Subsequently, we advance to large-scale agentic task synthesis, where we generate over 1,800 distinct environments and 85,000 complex prompts. This extensive synthesized data drives the RL process, significantly enhancing the model’s generalization and instruction-following capability in the agent context.
I’ve had an intuition that there will be great rewards(pun!) for people who can create really high-fidelity environments and let LLMs take a crack at it. One I can think of is the stock market. - depseek v3.2 paper
When I was working at a hedge fund, we spent a lot of time creating a high-fidelity backtester, which is finance for the environment. And once we had a good enough backtester, it was only a matter of time before smart people figured out money-making strategies.
Refs
[1] https://openreview.net/forum?id=4OsgYD7em5
[2]